
TLDR: この記事はテキストアドベンチャーゲームと物語生成言語モデルの違いを例として、機械学習モデル(特に生成型機械学習モデル)がゲームとアートの橋渡しをする技術になりうるのではないかということを考えたポエム的な記事です。
ゲームとアートの違い
ここでまず、アートとゲームとは何かというのを定義したいと思います。一般的な意味とは少しずれた意味で用語を使っているのでご注意ください。
まず、世の中にはエンターテイメントというものがあります。エンターテイメントは所謂娯楽であり、ユーザー(鑑賞者)が感情を充足させるための行為です。
ここでエンターテイメントの中にはアートとゲームがあるとします。
アート:音楽、小説、絵画、映画、演劇が該当し、鑑賞者を感動させるための視覚的/音楽的/言語的な表現です。特徴として、アートは一方通行です。クリエイターが創作したものをユーザー(鑑賞者)は一方的に受け取ります。そして、アートの表現方法にルールはありません。ある程度の確立した様式はありますが、必ずしもそれに従う必要はなく、そうした定形様式を破ったからこそ新しいアートが誕生したという歴史もあります(現代音楽や現代美術など)。
ゲーム:囲碁、将棋などのボードゲーム、サッカーやバスケットボールなどのスポーツ、コンピューターゲーム/デジタルゲーム/ビデオゲームなどがこれに該当します。アートとの違いとして、ゲームにはルールと目的があります。そして、ユーザーはただ一方的に受容するのではなく、自ら主体的に行動する必要があります。
まとめると、以下の図のようになります。まず、エンターテイメントの中にゲームとアートがあります。アートとゲーム以外のエンターテインメントに何があるのか気になるところですが、とりあえずそれは置いておきます。
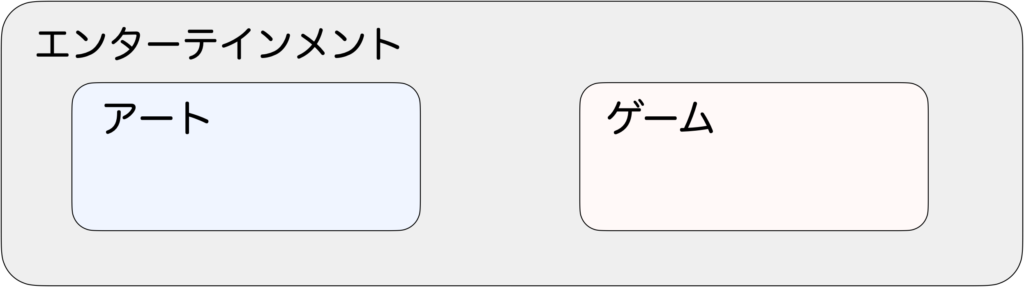
そして、アートとゲームには以下のような違いがあります。
| ユーザーの行動 | ルール/目的 | |
| アート | 一方的な受容 | ない |
| ゲーム | インターアクションが可能 | 決まっている |
前置きが長くなりましたが、何故機械学習がアートとゲームの橋渡しをしうる技術なのかを、テキストアドベンチャーゲームと物語生成言語モデルを例に挙げて説明します。
テキストアドベンチャーゲーム
テキストアドベンチャーゲームというのは1970代に登場したColossal Cave AdventureやZorkなどの、ユーザーの行動をテキスト入力で指定しながら進んでいくゲームです。
2018年にMicrosoftが発表したTextWorldというテキストアドベンチャーゲームのプラットフォームというのがありますが、そちらのウェブサイトでこれを体験することができます。
https://www.microsoft.com/en-us/research/project/textworld/try-it/
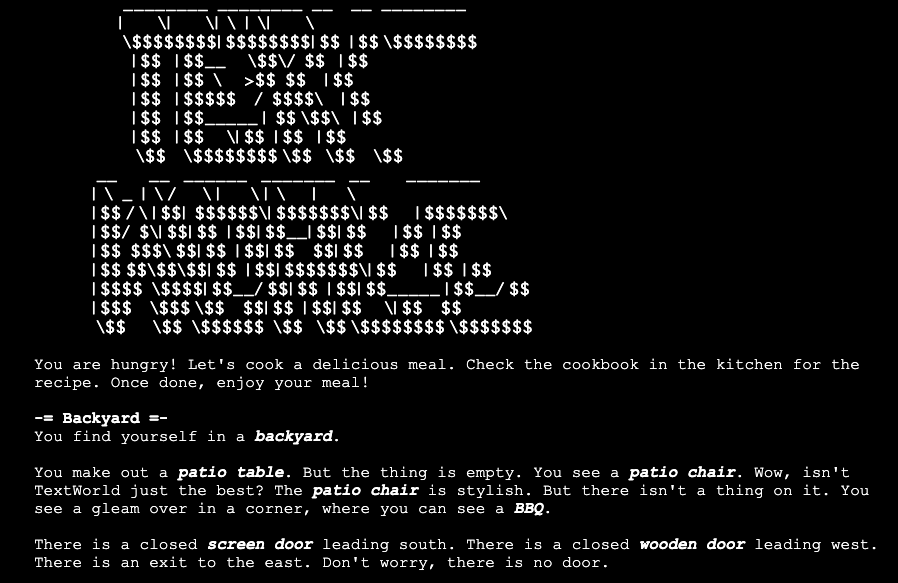
ちょっとやっていただければわかると思いますが、このゲームはテキストがユーザーが自由に入力できるものの、実際に受け付けてくれるテキストの幅は非常に狭いです。
helpコマンドを入力すると、受け付けてくれるコマンドリストが表示されます。
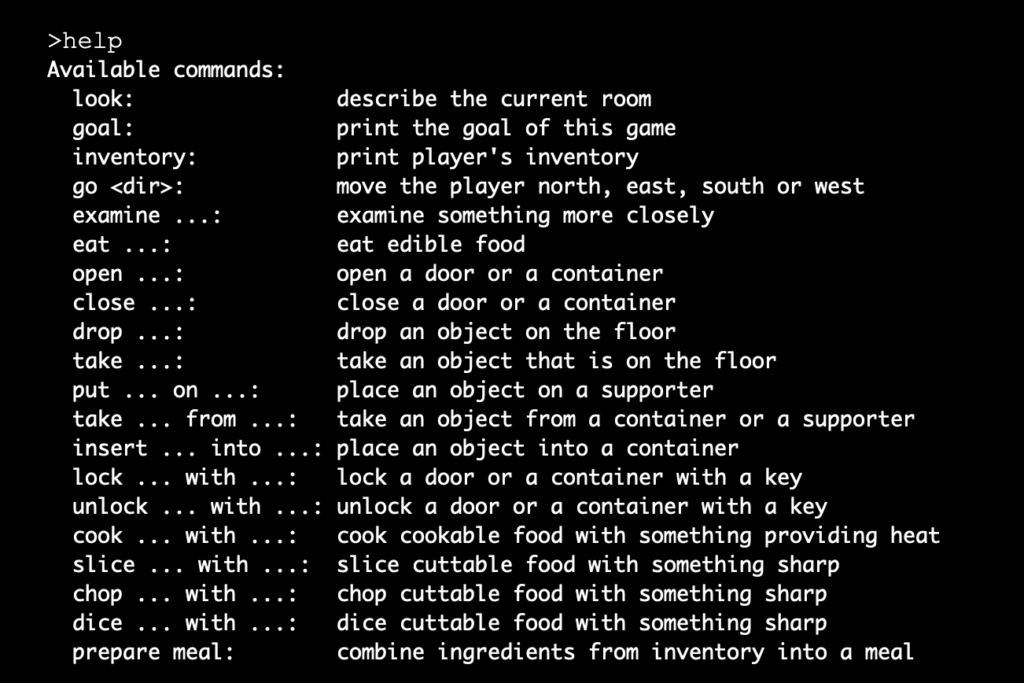
逆に言うとこれらのコマンドしか受け付けてくれません。
目的は、材料を集めて目的の料理を作ることです。しかし、今やると完全にクソゲーです。現代ゲーマーが耐えられる仕様にはなっていません。まずマップが無いので、どこにいるのか直感的にわかりません。何回北に行って、何回東に行けばスーパーに行けるのかいちいち頭の中で覚えていないといけません。
筆者は、料理の材料を集めることに成功しましたが、pantryにあるBBQでchicken legをcook しようとしました。そうすると、”You grilled the chicken leg”と表示されゲームオーバーになりました。レシピには、”roast the chicken leg”と書いてあるので、grillとroastの違いがいけなかったのでしょうか。しかし、日本人である私にはroastとgrillの違いはわかりません。英語的な意味でも難易度の高いゲームです。
TextWorldの凄さは、1970年代のゲームを再開発したことにあるのではなく、これらを強化学習エージェントによって解く仕組みを整えた点にあります。
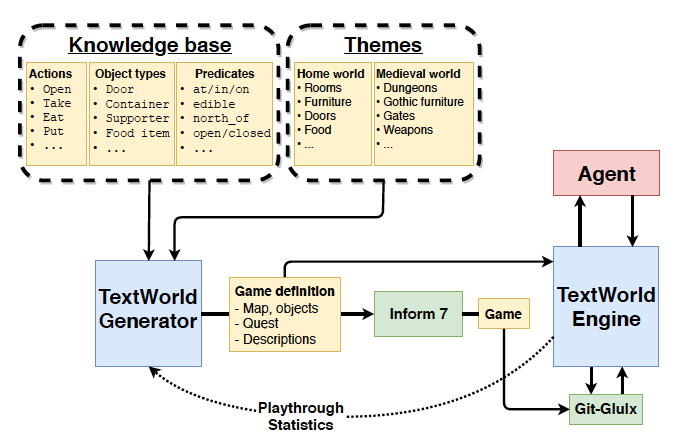
TextWorld内では動作やObjectの属性や位置などが定義されています。前述したように、ごく限られたテキスト入力しか受け付けてくれないのは、こうしたテキストアドベンチャーゲームにはルールがあり、そのルールに沿った行動しかできない点と、からです。
このように、テキストアドベンチャーゲームは小説と異なり、ユーザーがインターアクションすることが可能な媒体ですが、ゲームである以上ルールが存在し、そのルールに沿った行動しか取れないという制約があります。
物語生成言語モデル
ユーザーが主人公の行動を入力して、物語を進めるサービスには深層学習言語モデルを利用したものがいくつかあります。AI Dungeon, NovelAI, AI Buncho, AIのべりすとなどがありますが、上記のテキストアドベンチャーゲームと最も近いのはAI Dungeonと思われますので、AI Dungeonを例に挙げて比較してみます。
AI Dungeonでは、世界観の設定や主人公の属性を選ぶことができます。世界観をファンタジー、主人公を魔術師として、設定すると以下の物語が生成されます。

要約すると、
魔術師である主人公は「真実の書」と呼ばれる魔術書を探しに古代遺跡を訪れたところでした。しかし、その古代遺跡には誰もおらず、求めていた書物も見つからなかった
と書かれています。これを受けて、主人公はどのような行動を取るか、どのような発言をするかを手動で入力することができます。

例えば、「遺跡の最も近い村を訪れる」と入力すると、「3日間かかって近くの村に辿り着いた。そしてあなたはその村の酒場を訪れた」と表示されました。
一見すると、前述したテキストアドベンチャーゲームにとても似ているように見えます。大きな違いとしては、
- 物語生成言語モデルは、多様な入力を受け入れる。
- 目的やルールなどは無い。
という点です。AI Dungeonは、大規模ニューラルネットワークをモデルとして使用しているため、TextWorldに比べ、受け付けてくれるテキストの範囲が非常に広いです。ただし、目的やルールなどが無いという点はTextWorldに劣る点と言えるかもしれません。上述した例だと、古文書を探すことが目的であるように見えますが、その目的を達成できたとしても、ゲームクリアとなるわけではありません。
TextWorldと物語生成言語モデルの違い
| 入出力の自由度 | ルール/目的 | 離散/連続 | 矛盾 | |
| TextWorld | 低い | 厳密に決まっている | 離散的 | 発生しにくい |
| 物語生成言語モデル | 高い | 存在しない。制御困難。 | 連続的 | 発生しやすい |
TextWorldと物語生成言語モデルの違いを上にまとめてみました。この対応関係は最初に定義したアートとゲームの関係に似ているのではないでしょうか? 物語生成言語モデルはルールが緩いので、よりアートに近いと言えるでしょう。それに対し、TextWorldはルールが厳密に決まっているのでゲーム寄りです。
最初にアートは一方的に鑑賞者が受容するものと定義しましたが、鑑賞者がインターアクションを行えるアートも実は存在します。これらはインターアクティブアートと呼ばれていますが、個人的にはゲームとアートの中間に存在するものと考えられます。
上記サイトにインターアクティブアートがよくまとまっています。ユーザー(鑑賞者)が触ったり声を吹き込むことによって、映像や音楽が出力される形式のアート、それがインターアクティブアートです。
世の中に存在する画像生成AIや物語生成AIは創作補助ツールとしての使いみちもありますが、ユーザー(鑑賞者)が入力したテキストに対応して画像やテキストを出力するインターアクティブアートであると捉えることもできます。
インターアクティブアートは機械学習以前から存在していました。それなのに知名度が一般の一方通行的なアートと比べて圧倒的に低かったのは何故でしょうか? それは鑑賞者がインターアクションを行った際にアートとしての品質を保つのが難しいからと考えられます。ゲームにルールが存在するのも同じ理由です。ユーザーがインターアクションできる代わりにゲームには厳密なルールが存在します。このルールがあるからこそ、エンターテインメントとしての品質がある程度担保されます。
| ユーザーの行動 | ルール/目的 | |
| アート | 一方的な受容 | ない |
| インターアクティブアート | インターアクションが可能 | ない |
| ゲーム | インターアクションが可能 | 決まっている |
まとめると上記のようになります。生成型AIはアート、インターアクティブアート、ゲーム、それぞれにどう応用可能か議論していきます。
生成AIはアートかゲームかインターアクティブアートか。
アートとしての生成AIの使いみち
これは既に確立していると思います。画像生成AIをイラスト描画に使用したり、文書生成AIを小説執筆補助に使っている例は既に多く見られます。
インターアクティブアートとしての生成AI
こちらも既にある程度の地位を確立していると言えるでしょう。ラーメンを手づかみで食べる樋口円香や爆乳機関車などはエンターテインメントとして既に成立していると思います。アート生成の補助としての画像生成とインターアクティブアートとしての画像生成の違いは、完成された生成物のみを楽しむ場合はアートであり、プロンプトを色々といじって異なる画像が生成される過程を楽しむのであればそれはインターアクティブアートと言えると思います。
ゲームへの生成AIの使い道
こちらはまだあまり探索されていないように感じます。それには主に2つ理由があると考えられます。
注:混同を防ぐために注記しておきますが、ここで言うゲームは一般的な意味でのゲームではなく、最初に定義した意味でのゲームです。一般的にはゲームの範疇に入るRPGには物語があり、音楽があり、イラストがあります。これらは最初の定義ではアートの部類に入ります。したがってほとんどのコンピューターゲームはアート部分を内包しており、純然たるゲームは囲碁やスポーツなどが該当します。
AIの連続的表現とゲーム空間内の離散的表現の齟齬
前述したように、ゲームにはルールがありますが、生成型AIはルールに従ってくれません。また、ニューラルネットワークのモデルは連続空間のベクトルとして画像やテキストを表現しますが、ゲームではキャラクターやアイテムは離散的なオブジェクトとして表現されています。
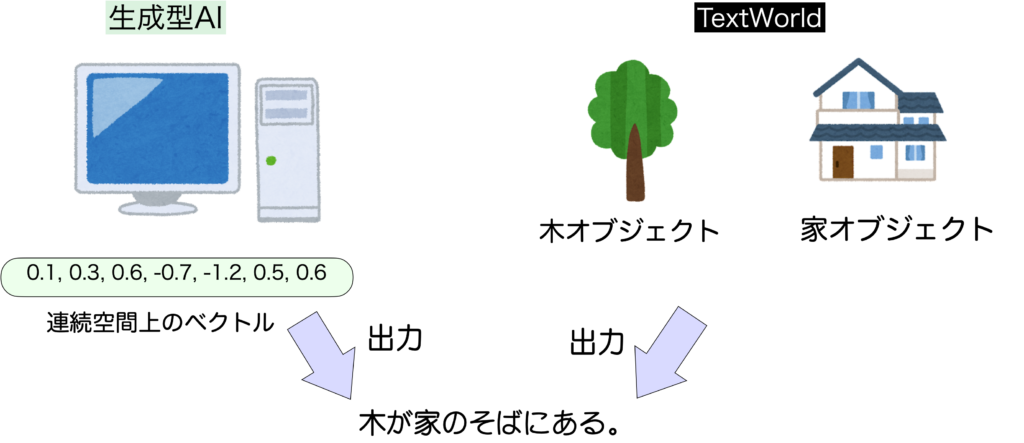
上図の例だと、TextWorldに代表されるテキストアドベンチャーゲームの環境では、木や家などは変数として明示的に定義されています。そこからルールに沿って、木の座標と家の座標が近ければ「木が家の傍にある」と出力することができます。これに対し、生成型AIが「木が家のそばにある」と出力した際、木や家は明示的には存在しません。これは生成型AI(あるいはニューラルネットワーク全般)が画像や文章を連続的な数値のベクトルとして表現するからです。そのベクトルに木は内在的に表現されているかもしれませんが、その保証はありません。次の文章では木はなかったことになるかもしれません。それに反し、テキストアドベンチャーゲームでは実体を明確に定義するためにこうした矛盾は起きません。
元来、機械学習モデルとルールベースは相性が悪いと言われていますが、こうした離散的な表現と連続的な表現の齟齬がゲームに不可欠なルールと生成AIとの相性を悪くしているとも考えられます。
解決案1:機械学習モデルをゲームに組み込もうとするのであれば、それをキャラクターやアイテムなどのオブジェクトと対応させるプロセスや、機械学習モデルの出力をルールに落とし込むためのプロセスが必要になります。離散的なプロセスを含むシステムの最適化には一般的には強化学習が有効です。
注:ゲームへの強化学習の応用は既に非常に多く研究されています。ただし、ほとんどの応用事例は強化学習を使ってゲームにどう勝つかを主眼に置いたものです。ここでは、元来機械での処理が難しかった画像や言語を高精度に連続ベクトルとして表現する機械学習モデルをどのようにゲームに組み込めるかの議論をしています。
解決案2:あるいは全てが連続ベクトル上で表現されたゲームというのも将来的には出現するかもしれません。
AI(機械学習)の出力の予測不可能性
また、AI(機械学習)がルールに従ってくれないということは予測不可能な出力をするということでもあります。ゲームには決められたルールがあるため、ゲーム内で起こる出来事は基本的には全て想定内の出来事です。ユーザーは、プレイを続けることによってパターンを理解していき攻略を進めていきます。それはゲームの面白さの基本的な要素と言えるでしょう。しかし、機械学習が予測不可能な出力を繰り返し、パターンが学習不可能になってしまうと、ユーザーは面白さを感じることができません。この点も、機械学習をゲームに応用しようとする際への乗り越えなければならない課題であるように思えます。
解決案:モデルをうまく制御するなどの単純な解決方法もありますが、予測不可能性自体が面白いと思える環境を作り上げるという道もありうると思います。具体的には思いつきませんが、後者は既存のゲームの概念を広げてくれる新しい要素となりうる可能性を秘めているように思えます。
結論
現在の生成AIは1.アートの補助ツールとしての使いみちが最も有力視されており、2.インターアクティブアートとしての使いみちも見い出しつつあります。3.ゲームへの使い道はまだ模索されるべき余地が残されていますが、今後もアートとゲームの垣根を埋めていく技術として期待が持てると思います。


Comments